
こんにちは!AIサービス開発室の鈴木生雄です。今回は個人的に注目している音声生成AIの分野でVibeVoiceというオープンウェイトなモデルが非公開になったことについてお届けしたいと思います。
VibeVoiceは、2025年8月26日にMicrosoftからオープンウェイトな長尺多声音声生成モデルとして公開されました。
VibeVoice: A Frontier Open-Source Text-to-Speech Model
最長90分の長尺かつ4人までの多声に対応したモデルということで、当初の対応言語が英語または中国語のみではありましたが、個人的にとても注目していたプロジェクトでした。しかし、9月5日に突然、1.5Bと7Bの二つあったモデルのうち、7Bのウェイトと関連するソースコードがレポジトリから削除されました。VibeVoiceのGithubレポジトリには以下のように記されています。
2025-09-05: VibeVoice is an open-source research framework intended to advance collaboration in the speech synthesis community. After release, we discovered instances where the tool was used in ways inconsistent with the stated intent. Since responsible use of AI is one of Microsoft’s guiding principles, we have disabled this repo until we are confident that out-of-scope use is no longer possible.
要するに、VibeVoiceが意図しない使われ方をしているのを発見したので公開を止めたということのようです。実はVibeVoiceには、サンプルの短い音声ファイルを用意すると、そこからゼロショット(つまり学習なし)でサンプル音声と同じ声色でTTS(Text-To-Speech)できるという機能があったので、これを悪用するケースが見つかったのではないかと推察しています。
実際に自分の声のサンプルを作ってTTSしたところ、なかなかに似ているなと思いました。(私の声を知らない人は聴いても仕方がないかもしれませんが、一応実験した結果の音声を以下のとおり紹介しておきます。)対応言語でない日本語でこの調子なら、英語や中国語であればもっと似せることができるのかもしれません。私はこの結果を受けて、フェイク音声が出回ることで社会的信用を失うことを想像して、とても怖いことだなと感じました。ちなみにタイムリーなニュースとして、9/17にイタリアでAI規制法が可決され、ディープフェイクで被害が生じた場合は最長5年の禁錮刑を含む厳罰が科されることになったということがありました。それくらい現実的な問題になっているということです。
それから、プリセットされていたサンプルの登場人物を4者の声を使った多声音声生成の実験結果は以下のような感じでした。
こんな音声コンテンツがエンドトゥーエンドで作れるのはとても便利だと思うので、声色を再現する機能だけを除いて、再公開されないかなあと一縷の望みを抱いております…。
最後に技術的なお話を少し。今回、VibeVoiceを動かすに当たってはMac Mini M4 Pro 64GB Unified Memoryを使いました。AppleシリコンにはGPU用APIであるMetal、Metal上で動くMetal Performance Shaders(MPS)やMPSGraphというライブラリが用意されています。これらはざっくり言うと、NvidiaのCUDA+cuDNN / cuBLASに相当するものです。VibeVoiceで用いられている深層学習フレームワークのPyTorchでは、デバイスをcudaまたはmpsと指定するだけで、Nvidia環境またはApple環境のいずれでもGPUを利用することができます。
以下はVibeVoiceのデモプログラムをcuda用ではなくmps用にするために私が作成したパッチです。こんな感じで少し手を加えるだけでMacでも動かすことができました。
--- gradio_demo.py.bak.20250831-000557 2025-08-31 00:05:57
+++ gradio_demo.py 2025-08-31 00:22:32
@@ -19,7 +19,38 @@
import torch
import os
import traceback
+# === begin: gradio_client schema compatibility shim (bool additionalProperties) ===
+try:
+ import gradio_client.utils as _gutils
+ _orig_get_type = _gutils.get_type
+ _orig_conv = _gutils._json_schema_to_python_type
+ def _safe_get_type(schema):
+ # JSON Schema で True/False 単体が来るケースに対応
+ if isinstance(schema, bool):
+ # True: "any object" とみなし、False: "never/null" 相当
+ return "object" if schema else "null"
+ return _orig_get_type(schema)
+
+ def _safe_json_schema_to_python_type(schema, defs):
+ # schema 自体が bool の場合に対応
+ if isinstance(schema, bool):
+ return "dict" if schema else "None"
+ # additionalProperties が bool の場合に対応
+ ap = schema.get("additionalProperties") if isinstance(schema, dict) else None
+ if isinstance(ap, bool):
+ schema = dict(schema) # 浅いコピーで改変
+ # True は「任意の値」を許可、False は「許可しない」→ ここでは空オブジェクト相当で受け流す
+ schema["additionalProperties"] = {} if ap else {"type": "null"}
+ return _orig_conv(schema, defs)
+
+ _gutils.get_type = _safe_get_type
+ _gutils._json_schema_to_python_type = _safe_json_schema_to_python_type
+except Exception: # 失敗しても致命ではない
+ pass
+# === end: gradio_client schema compatibility shim ===
+
+
from vibevoice.modular.configuration_vibevoice import VibeVoiceConfig
from vibevoice.modular.modeling_vibevoice_inference import VibeVoiceForConditionalGenerationInference
from vibevoice.processor.vibevoice_processor import VibeVoiceProcessor
@@ -32,7 +63,7 @@
class VibeVoiceDemo:
- def __init__(self, model_path: str, device: str = "cuda", inference_steps: int = 5):
+ def __init__(self, model_path: str, device: str = "mps", inference_steps: int = 5):
"""Initialize the VibeVoice demo with model loading."""
self.model_path = model_path
self.device = device
@@ -56,9 +87,11 @@
# Load model
self.model = VibeVoiceForConditionalGenerationInference.from_pretrained(
self.model_path,
- torch_dtype=torch.bfloat16,
- device_map='cuda',
- attn_implementation="flash_attention_2",
+ torch_dtype=(torch.float16 if self.device=='mps' else torch.float32),
+ low_cpu_mem_usage=True,
+ device_map={'': self.device},
+ attn_implementation='sdpa',
+ use_safetensors=True,
)
self.model.eval()
@@ -1116,13 +1149,13 @@
parser.add_argument(
"--model_path",
type=str,
- default="/tmp/vibevoice-model",
+ default="microsoft/VibeVoice-1.5B",
help="Path to the VibeVoice model directory",
)
parser.add_argument(
"--device",
type=str,
- default="cuda" if torch.cuda.is_available() else "cpu",
+ default="mps" if torch.backends.mps.is_available() else "cpu",
help="Device for inference",
)
parser.add_argument(以下はデモプログラムのスクリーンショットです。なお、このデモプログラムは、Gradio(グラディオ)というAIモデルのデモを行うWebアプリケーションを簡単に作ることができるPythonのライブラリで実装されていました。
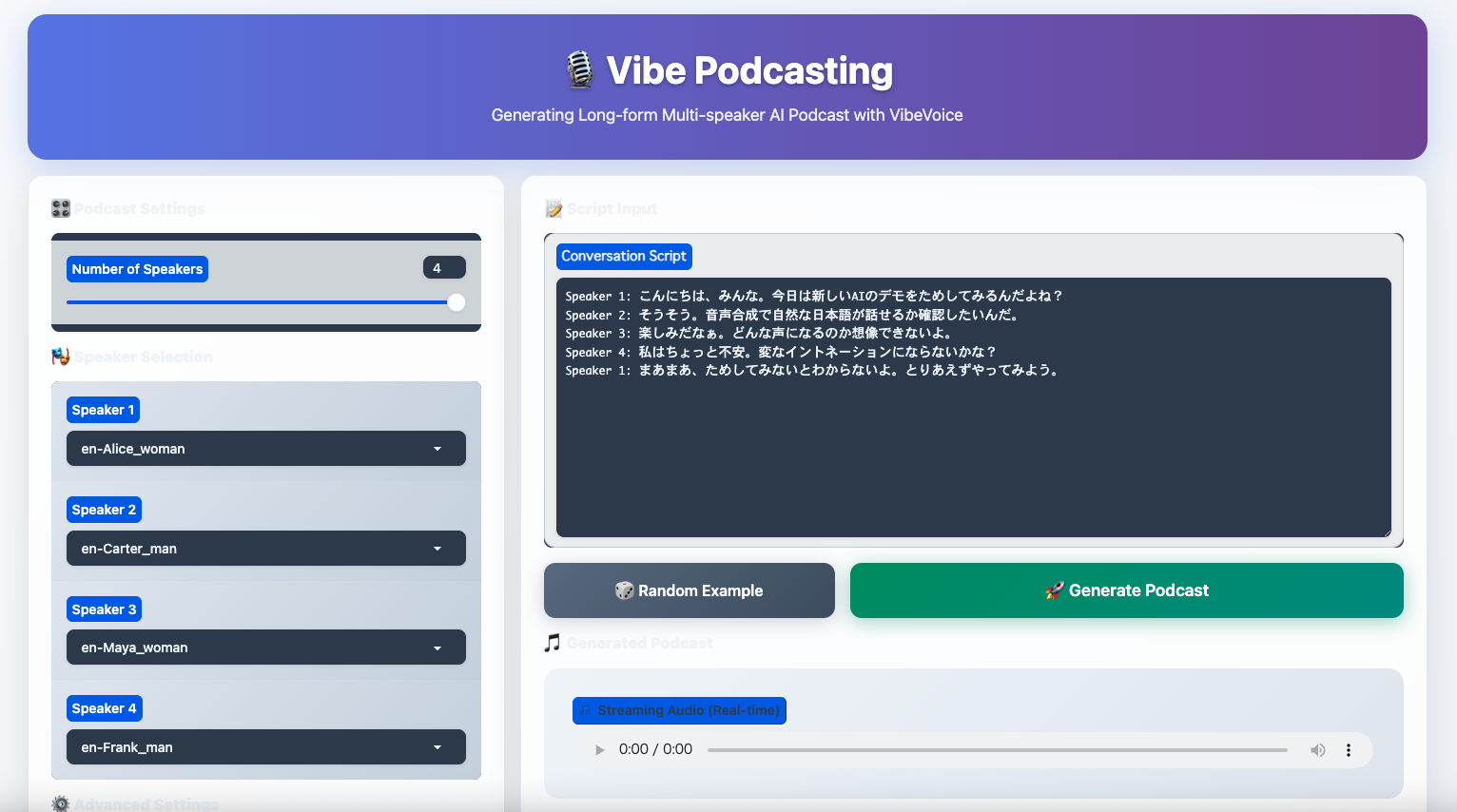
コンテンツの生成を容易にするツールやサービスが充実すればするほど、ディープフェイクの問題も増えるのは間違いないと思うので、電子透かし等の技術面や、法律やガイドライン等のルール面での防止施策がますます重要になってくるでしょう。AIを活用する企業や一般消費者としては、AIの実力がどの程度まで到達しているのか、それによってどんな社会情勢の変化が起きようとしているのかを日頃からウォッチして、AI活用の方針を調整していくのが良いと思います。