
こんにちは!AIサービス開発室の鈴木生雄です。今回は6/16に投稿したエントリーで取り上げたMinionについて、実際にデモアプリを動かして体験してみた件についてお届けします。
(前回記事「MinionとNVIDIA H100のConfidential Computingモードのセキュリティ解説」をまだご覧でない方はこちらからどうぞ)
デモの概要
前回は Minion のアーキテクチャを理論面から解説しました。今回は公開されている Streamlit 製デモアプリ を使い、
- ローカルモデル:llama3.2
- フロンティアモデル:ChatGPT-4o
を協調させて課題「What is the goal of minion?」を解かせた結果を報告します。
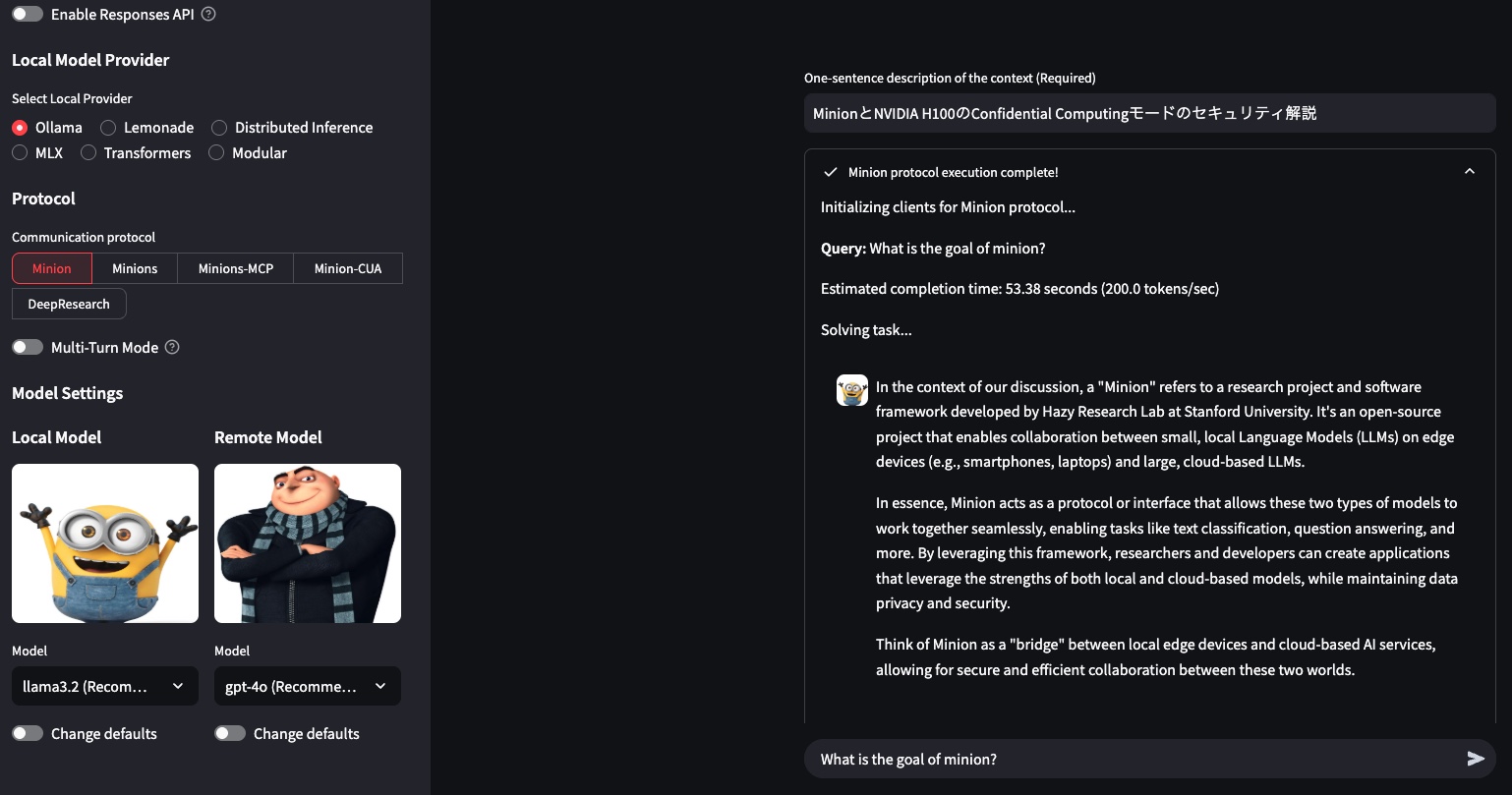
アプリを起動すると上のような画面が表示されるので、コンテキストとして前回のブログの内容、すなわちMinionの概要を表す文章を与えた上で、プロンプトに「What is the goal of Minion?(日本語訳:Minionの目標は何?)」と入力して送信します。そして、この問いをllamaとChatGPTに協働して解かせます。
返ってきた回答は以下のとおりでした。回答内容は問題なしです。
The goal of Minion, a research project and software framework developed by Hazy Research Lab at Stanford University, is to enable collaboration between small, local Language Models (LLMs) on edge devices and large, cloud-based LLMs. Minion acts as a protocol or interface that facilitates seamless interaction for tasks such as text classification and question answering. It emphasizes maintaining data privacy and security, effectively serving as a bridge between local edge devices and cloud-based AI services. This allows researchers and developers to leverage the strengths of both local and cloud-based models in a secure and efficient manner.
日本語訳:
スタンフォード大学Hazy Research Labが開発した研究プロジェクトおよびソフトウェアフレームワークであるMinionの目標は、エッジデバイス上の小規模なローカル言語モデル(LLM)と大規模なクラウドベースのLLM間の連携を可能にすることです。Minionは、テキスト分類や質問応答などのタスクにおけるシームレスな連携を促進するプロトコルまたはインターフェースとして機能します。データのプライバシーとセキュリティの維持を重視し、ローカルエッジデバイスとクラウドベースのAIサービス間の橋渡しとして効果的に機能します。これにより、研究者や開発者は、ローカルモデルとクラウドベースモデルの両方の長所を安全かつ効率的に活用できます。
テスト環境
動作環境は以下のとおりです。フロンティアLLMとローカルLLMの組み合わせを変えて実験するのも面白そうですが、今回はそこまでは手を出さずに、GPT-4oとllama3.2(パラメタ数3B)でのみ試しました。
| 項目 | 内容 |
|---|---|
| ローカル SoC/GPU | Apple M4 Pro 内蔵 GPU |
| OS / Python | macOS Sequoia 15.5 / Python 3.12 |
| ローカルLLMランタイム | ollama 0.9.3 |
| フロンティア LLM | GPT-4o |
| ローカルLLM | llama3.2:3b |
デモアプリの回答作成の流れ
アプリ回答の流れをシーケンス図で表すと以下のとおりとなります。Llama3.2が長文コンテキストを要約して、最終回答に必要な内容に絞った上でGPT-4oに要約(コンテキスト)+質問と言う形で渡している所がポイントです。
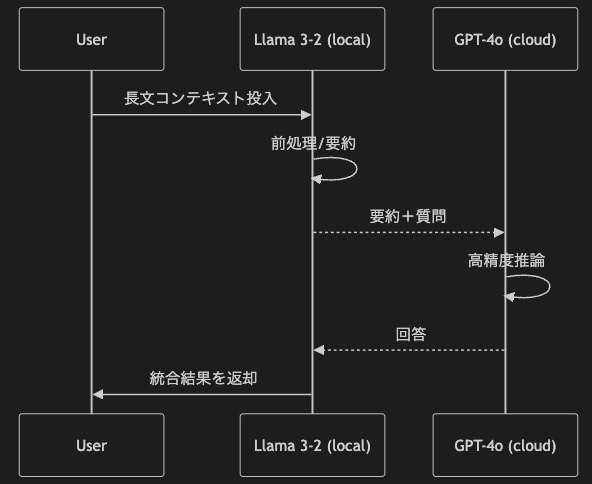
つまり、
- タスク分解と要約送信は自動化済み
- GPT-4o には要点のみを送り、API コストを抑制
ということです。
実測データ
Llama3.2とGPT-4oの送受信トークンの実測データは以下のとおりでした。
| 指標 | Llama 3.2 | GPT-4o |
|---|---|---|
| 送信トークン | 6,732 | 2,632 |
| 受信トークン | 165 | 660 |
| 合計トークン | 6,897 | 3,292 |
| 推論時間 | 15.09 s | 14.61 s |
GPT-4o の料金は 入力が$5/M token 、出力が $20 / M tokenですから、API コスト試算としては以下のようになります。
| 方式 | 課金対象トークン | 概算コスト |
|---|---|---|
| Minion 協調 | 2,632 input + 660 output | $0.026 |
| もし全文を GPT-4o のみで処理(= 2 632 + 6 732 input + 660 output と仮定) | 9,364 input + 660 output | $0.060 |
協調実行 $0.026 vs 全文GPT-4o $0.060 ということで、約 56 % コストを削減できたと言えそうです。
見えてきたメリット
- API 費用の削減 … コンテキストが長くなるほど効果増大
- プライバシー保護 … 機微情報はローカルで要約し、クラウドへは送らない
- 性能の“いいとこ取り … 要約や軽い推論は Llama 3-2、難問は GPT-4o
体験してわかった課題感
| 観点 | 気づき |
|---|---|
| レイテンシ | ローカル+クラウドの“合算”なので対話アプリではやや待たされる |
| セットアップ | ollamaは簡単だが、モデル量子化や RAM 消費の調整は依然必要 |
| ローカル精度 | Llama 3.2 3B は要約品質に頭打ち。より大きなモデルだと VRAM 要件が上がる |
まとめ
- 協調実行で GPT-4o の API 請求額を約半分に削減
- macOS + Apple M4 Pro + ollama という“手軽なローカル環境”でも再現可能
- 費用とリスクの両立策として現実的 ─ ただしレイテンシとローカル GPU メモリは要注意
クラウド単独でもローカル単独でもない “いいとこ取り” の選択肢として、Minion の可能性は十分に感じられました。興味のある方はぜひ試してみてください!